¿Qué es Kusto?
Para los que no hayan oído hablar nunca de este lenguaje, Kusto (también llamado Kusto Query Language o KQL) es un lenguaje de consulta creado y diseñado para hacer consultas de volúmenes muy grandes de información de datos estructurados o semiestructurados, incluyendo métricas, logs y telemetría en escenarios de analítica en tiempo real (o casi en tiempo real). Además, Kusto es el lenguaje utilizado en Azure Data Explorer, así que si has de tocar esta herramienta, necesitas Kusto sí o sí, no vale SQL.
De SQL Server a Kusto - Conceptos básicos
Durante toda mi vida profesional he trabajado principalmente con SQL Server como motor de bases de datos. Entonces, pasar de SQL a Kusto ha supuesto un pequeño cambio de mentalidad y, porque no decirlo, un pequeño aprendizaje. Sí que también había tocado MySQL / MariaDb y PostgreSQL (poca broma con este último, es potente, rápido y encima Open Source), pero al final no deja de ser SQL, con sus SELECT, sus FROM, WHERE, etc. Sin embargo, Kusto funciona distinto.
Una de las particularidades que más chocan cuando estás empezando a experimentar con Kusto es el hecho de que todo va con pipes. A priori todo se ve de un modo más visual y con un lenguaje más “natural” y ordenado. Por ejemplo, para hacer una búsqueda de todas aquellas personas que se llaman Ferran (y que me devuelva todos los campos de la tabla), la consulta en Kusto sería:
Users
| where Name == "Ferran"
A nivel de sintaxis, también hay diferencias notables entre SQL y Kusto. Hay algunas palabras reservadas que sí que son exactamente iguales, tanto a nivel de escritura como de comportamiento, como por ejemplo, WHERE, que se utiliza para filtrar por alguno (o varios) campos. Sin embargo, hay otros casos que tienen su palabra concreta y que hacen lo mismo, pero no se llaman igual, y un claro ejemplo de esto es cuando queremos agrupar por alguno (o varios) campos. En SQL Server se utiliza GROUP BY, pero en Kusto se utiliza summarize by:
Users
| where Name == "Ferran"
| summarize Total = count() by datetime_part("Year", Birthdate)
Esta consulta lo que hace es filtrar todos aquellos usuarios que se llamen Ferran y los agrupa por el año de la fecha de nacimiento.
Lo mismo sucede con los campos, si en SQL Server queremos que la consulta nos devuelva un número determinado de campos, escribimos los campos después del SELECT. Bien, en Kusto esto no es así, ya que para ello, devolveremos los campos que queremos utilizando la sentencia project:
Users
| where Name == "Ferran"
| project Name, Surname, Birthdate, Address
Esta consulta lo que hace es devolverme el nombre, apellido, fecha de nacimiento y dirección filtrando por todos aquellos usuarios que se llamen Ferran.
Diferencias entre SQL y Kusto
Partimos de la base (y esto es muy importante) de que SQL es un lenguaje orientado más a modelos y sistemas de bases de datos transaccionales y/o relacionales que permitan y deban persistir información. En cambio, Kusto está más orientado a la observabilidad y el análisis de los datos en tiempo real, por tanto, estamos hablando de sistemas de bases de datos analíticos que cuentan y tratan con millones de registros a una velocidad que SQL no sería capaz. En este escenario, Kusto gana por goleada, ya que está diseñado para esto.
Otra de las diferencias es que los nombres tanto de la sintaxis como los campos son case-sensitive. Es decir, has de respetar las mayúsculas/minúsculas. Por ejemplo, en SQL Server da igual si escribes SELECT * FROM NOMBRETABLA que select * from nombretabla, o incluso los campos, puedes buscar por Nombre, NOMBRE, nombrE, que te lo encuentra igual. En Kusto esto no es así del todo. Si el campo en la tabla se llama Nombre, has de poner exactamente Nombre para que aparezca la información. Si lo escribes mal, puede ser que no devuelva el resultado esperado. De todos modos, el resto de campos que forman parte de la sintaxis (las palabras reservadas del lenguaje, tales como where, count, etc.), la norma indica que hay que escribirlos en minúsculas.
Mientras que en SQL puedes hacer CRUD (create, update y delete) para crear, actualizar y borrar datos respectivamente, Kusto es un lenguaje Read-Only, solo permite leer datos, no permite modificar ni eliminar. Esto tiene todo el sentido del mundo, ya que si Kusto se utiliza básicamente para el análisis y para leer métricas, logs y grandes volúmenes de datos en tiempo real, se ha de garantizar que los datos no sufran ninguna alteración externa.
Tabla comparativa
Os dejo una tabla comparativa para que podáis ver la traducción entre SQL y como haríamos lo mismo en Kusto:
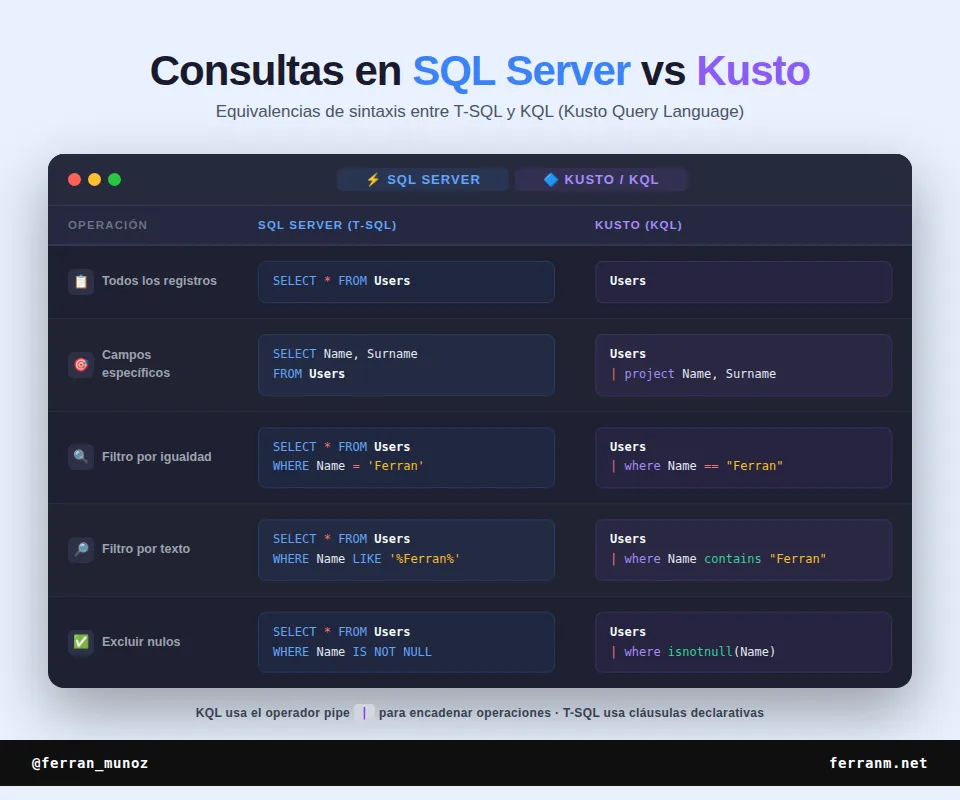
Conclusión
Si vienes de SQL como ha sido mi caso, Kusto te parecerá extraño. Pero con esta entrada quiero poner de manifiesto que tiene una curva de aprendizaje relativamente pequeña y todo es cuestión de cambiar el chip. En pocos días estarás haciendo consultas y entendiendo el funcionamiento básico para poder hacerlas sin tener que recurrir a apuntes.
En próximos posts profundizaré más sobre el tema y hablaré de otras figuras del lenguaje como son las funciones, las vistas materializadas o snapshots.